Python提供了大量的学习心得工具,下面做一些基本介绍。 首先是NumPy,即“Numerical Python”,是Python的一种开源的数值计算扩展。它可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。
提到了Numpy,自然也要提到SciPy (Scientific Python),Scipy在Numpy基础上扩展了更多功能,比如回归,傅里叶变换等。 (素材大多取自http://www.python-course.eu/)。
还有一个基本的数据处理工具pandas,简单来说就是一个Python版的excel。
和Matlab对比
如果想要匹配Matlab这种变态的需求,那么我们需要NumPy,Scipy,Matplotlib和pandas。这一套东西熟悉了之后,那么Matlab真的不用买了,或者费劲找资源了。
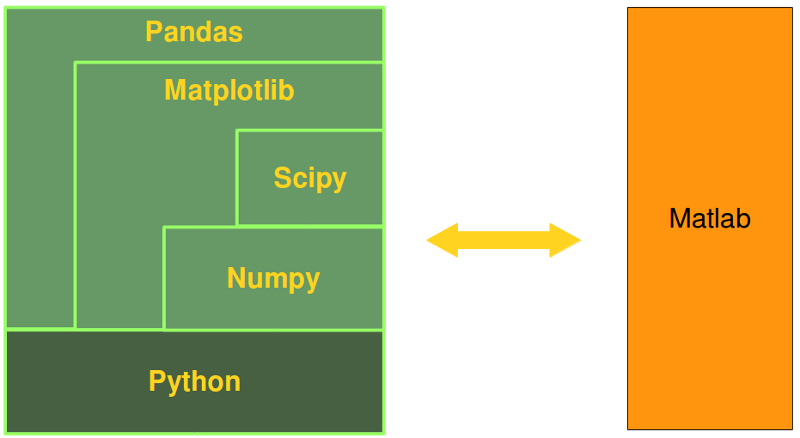
上图的这些东西,我们需要从下到上安装,防止出现依赖问题,或者直接下载anaconda,一键完成。
学习路线图
由上图可见,我们学习这套工具最好是从Numpy开始,然后Scipy和Matplotlib,最后Pandas。
总之,为了学习心得方便,我们从Numpy开始吧。
工具
强烈建议使用Jupyter,保证你的学习效率提高数倍。如果安装的是anaconda,那么不用单独安装了。怎么用的话,网上很多教程我就不详细说了。我这里的所有内容都是用Jupyter写的。
初体验
import numpy as np
temperature_c = [25.3, 24.8, 26.9, 23.9] # 摄氏温度
如果想要计算华氏温度,原生Python方法需要:
temperature_f = [x * 9 / 5 + 32 for x in temperature_c]
print(temperature_f)
[77.54, 76.64, 80.42, 75.02]
但是如果是用numpy array就简单了:
np_c = np.array(temperature_c) # 转为numpy array,ndarray
np_f = np_c * 9 / 5 + 32
print(np_f)
[ 77.54 76.64 80.42 75.02]
平均分布
我们可以使用Numpy提供的arange和linspace构建等差数列
arange
np.arange(start, stop=None, step=1, dtype=None)
详细用法,抄一段文档如下(第一次看建议略过):
Docstring:
arange([start,] stop[, step,], dtype=None)
Return evenly spaced values within a given interval.
Values are generated within the half-open interval ``[start, stop)``
(in other words, the interval including `start` but excluding `stop`).
For integer arguments the function is equivalent to the Python built-in
`range <http://docs.python.org/lib/built-in-funcs.html>`_ function,
but returns an ndarray rather than a list.
When using a non-integer step, such as 0.1, the results will often not
be consistent. It is better to use ``linspace`` for these cases.
Parameters
----------
start : number, optional
Start of interval. The interval includes this value. The default
start value is 0.
stop : number
End of interval. The interval does not include this value, except
in some cases where `step` is not an integer and floating point
round-off affects the length of `out`.
step : number, optional
Spacing between values. For any output `out`, this is the distance
between two adjacent values, ``out[i+1] - out[i]``. The default
step size is 1. If `step` is specified, `start` must also be given.
dtype : dtype
The type of the output array. If `dtype` is not given, infer the data
type from the other input arguments.
Returns
-------
arange : ndarray
Array of evenly spaced values.
For floating point arguments, the length of the result is
``ceil((stop - start)/step)``. Because of floating point overflow,
this rule may result in the last element of `out` being greater
than `stop`.
重点说下:
- arange返回等间距数组,范围是[start, stop)(包括start,但是不包括stop),与原生的range不同的是,arange返回的是ndarray,而不是iterator。
- 如果是非整数step,结果可能不准,建议使用linspace
a = np.arange(1, 10)
print('ndarray:', a)
# compare to range:
x = range(1,10)
print('range object:', x) # x is an iterator
print(list(x))
ndarray: [1 2 3 4 5 6 7 8 9]
range object: range(1, 10)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
linspace
linspace(start, stop, num=50, endpoint=True, retstep=False)
详细用法,抄一段文档如下(第一次看建议略过):
Return evenly spaced numbers over a specified interval.
Returns `num` evenly spaced samples, calculated over the
interval [`start`, `stop`].
The endpoint of the interval can optionally be excluded.
Parameters
----------
start : scalar
The starting value of the sequence.
stop : scalar
The end value of the sequence, unless `endpoint` is set to False.
In that case, the sequence consists of all but the last of ``num + 1``
evenly spaced samples, so that `stop` is excluded. Note that the step
size changes when `endpoint` is False.
num : int, optional
Number of samples to generate. Default is 50. Must be non-negative.
endpoint : bool, optional
If True, `stop` is the last sample. Otherwise, it is not included.
Default is True.
retstep : bool, optional
If True, return (`samples`, `step`), where `step` is the spacing
between samples.
dtype : dtype, optional
The type of the output array. If `dtype` is not given, infer the data
type from the other input arguments.
.. versionadded:: 1.9.0
Returns
-------
samples : ndarray
There are `num` equally spaced samples in the closed interval
``[start, stop]`` or the half-open interval ``[start, stop)``
(depending on whether `endpoint` is True or False).
step : float, optional
Only returned if `retstep` is True
Size of spacing between samples.
总的来说,就是返回一组个数为num的数列,[start, stop](如果endpoint=True),或者[start, stop)(如果endpoint=False)
# [1, 10],共十个数:
print(np.linspace(1, 10, 10))
# [1, 10),共十个数:
print(np.linspace(1, 10, 10,endpoint=False))
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 1.9 2.8 3.7 4.6 5.5 6.4 7.3 8.2 9.1]
我们在试试retstep有什么用处
# [1, 10],共十个数:
print(np.linspace(1, 10, 10, retstep=True))
(array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.]), 1.0)
可以看到,如果设为True, 返回值变为tuple类型(samples, step), step是样本间距
速度
Nunpy往往比原生Python计算要快。知道这么多够了,有兴趣自己查好了。
下一步
这部分仅仅大概体验了一下Numpy,下一步,真正开始了。
